

Jeśli pracowaliście już z testami regresji wizualnej, wiecie, że często w proces analizy trzeba zaangażować kilka osób, aby zdecydować, które zmiany są spodziewane, a które są błędami. Istnieją komercyjne narzędzia, takie jak SauceLabs, BrowserStack czy LambdaTest, które pomagają w testach wizualnych, ale ich koszt szybko rośnie – szczególnie, jeśli regresja wizualna nie jest priorytetem w projekcie.
W takich przypadkach świetną alternatywą jest rozwiązanie open-source – Visual Regression Tracker – które możemy zainstalować we własnej infrastrukturze i dzięki temu mieć pełną kontrolę nad środowiskiem testowym.
Kolejnym, bardziej zaawansowanym narzędziem open-source, które pozwala na wykrywanie potencjalnych regresji wizualnych przy użyciu Playwrighta, jest Visual Regression Tracker.
Visual Regression Tracker umożliwia skuteczne porównywanie zrzutów ekranu w celu identyfikacji zmian wizualnych i potencjalnych błędów. Jest to narzędzie, które można samodzielnie wdrożyć w swojej infrastrukturze, dzięki czemu mamy pełną kontrolę nad środowiskiem testowym.

Visual Regression Tracker to narzędzie open-source składające się z dwóch głównych elementów.
Pierwszym jest aplikacja do przechowywania wyników testów wizualnych, oferująca funkcje takie jak uwierzytelnianie użytkowników oraz oznaczanie ignorowanych obszarów w testowanych aplikacjach. Działa to podobnie jak maska w Playwright—gdzie maska również jest dostępna—jednak w tym przypadku ignorowane obszary można oznaczać bezpośrednio z poziomu aplikacji webowej. Możemy też decydować, co jest zatwierdzone dla każdej gałęzi, dzięki czemu cały zespół ma do tego dostęp poprzez aplikację webową, korzystając z własnych kont użytkowników.
Drugim elementem jest biblioteka, którą instalujemy w naszym frameworku do automatyzacji testów.
Visual Regression Tracker można zintegrować nie tylko z Playwright, ale także z innymi popularnymi frameworkami testowymi, takimi jak Robot Framework, Cypress czy CodeceptJS.
Dodatkowo instalacja zawiera REST API, które pozwala nam tworzyć własne integracje z Visual Regression Tracker, nawet jeśli korzystamy z narzędzia, które nie jest obecnie obsługiwane, np. frameworków do automatyzacji testów mobilnych.
Jak to działa?

Visual Regression Tracker korzysta z bazy danych PostgreSQL do przechowywania wyników testów. Alternatywnie obrazy można przechowywać w zewnętrznych storage’ach, np. Amazon S3. Drugi kontener odpowiada za frontend aplikacji, w którym mamy możliwość analizy i akceptacji/odrzucania wyników wizualnych.
Jak zainstalować to rozwiązanie?
Najprostszym sposobem na zainstalowanie Visual Regression Trackera jest skorzystanie ze skryptu instalacyjnego, który „pod spodem” pobiera i uruchamia odpowiednie kontenery Docker.
Robię to poprzez skorzystanie z komendy:
curl https://raw.githubusercontent.com/Visual-Regression-Tracker/Visual-Regression-Tracker/master/vrt-install.sh -o vrt-install.sh
chmod a+x vrt-install.sh
./vrt-install.sh
Podczas instalacji pobierane są wszystkie niezbędne pliki związane z kontenerami Dockera dla tego projektu. Ważne jest, aby przed uruchomieniem tego skryptu upewnić się, że Docker jest uruchomiony w systemie.
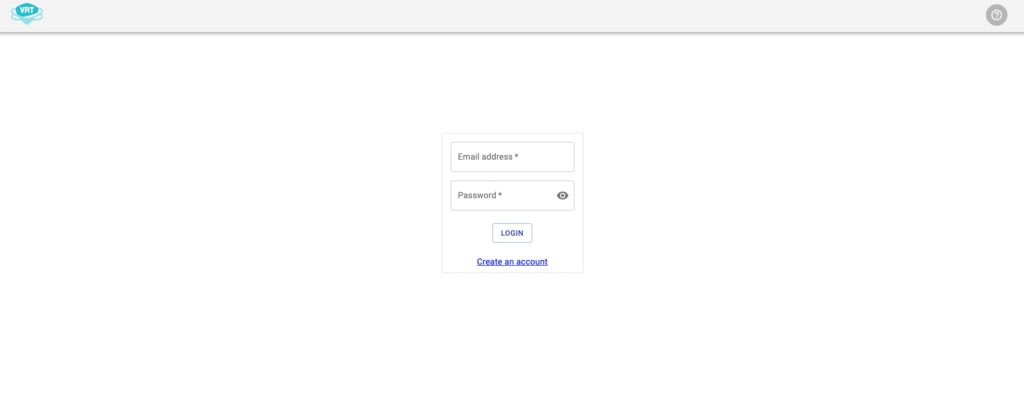
Po zakończeniu instalacji naszym oczom ukazuje się strona logowania do Visual Regression Trackera, który jest dostępny na porcie 8080. Aby się zalogować, musimy użyć danych użytkownika wygenerowanych podczas instalacji kontenerów Docker.
Oprócz zainstalowania Visual Regression Trackera za pomocą Dockera, konieczne jest również zainstalowanie biblioteki agent-playwright, która umożliwia integrację z naszymi testami automatycznymi.

Bibliotekę agen-playwright Instalujemy ją poprzez paczkę npm.
npm install @visual-regression-tracker/agent-playwrightPlik vrt.json
Jednym ze sposobów skonfigurowania lokalnej integracji z Visual Regression Trackerem jest użycie pliku konfiguracyjnego vrt.json. W tym pliku musimy ustawić apiKey, który można łatwo znaleźć podczas instalacji narzędzia.
Dodatkowo możemy skonfigurować opcję korzystania z tzw. miękkich asercji poprzez ustawienie parametru “enableSoftAssert”: true. Spowoduje to, że testy nie będą kończyły się błędem w przypadku wykrycia różnic wizualnych, a wszelkie błędy zostaną jedynie zalogowane w Visual Regression Trackerze.
Podejście do używania miękkich asercji może się różnić w zależności od zespołu i specyfiki projektu. Niektórzy preferują, aby testy zawsze przechodziły, a wyniki wizualnej regresji były sprawdzane ręcznie. Inni stosują bardziej restrykcyjne podejście, w którym każdy błąd powoduje niezaliczenie testu. Obydwa podejścia mają swoje zalety i wady – wybór zależy od kontekstu oraz specyfiki aplikacji.
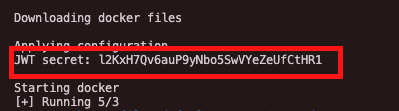
Token api do skopiowania dostępny jest podczas instalacji Visual Regression Trackera. Następnie token trzeba pobrać i wkleić w pliku vrt.json do parametru apiKey.
Opis pól:
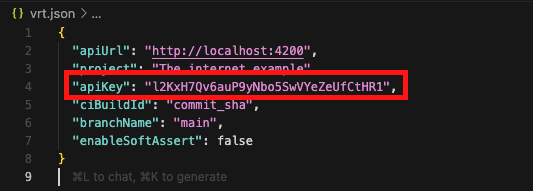
apiUrl– adres instancji Visual Regression Trackeraproject– nazwa projektu (domyślnie „Default project”)apiKey– klucz API wygenerowany przy instalacji DockeraciBuildId– identyfikator buildu (np. commit SHA, numer joba w Jenkinsie)branchName– nazwa gałęzi, której dotyczą testyenableSoftAssert– jeślitrue, testy nie failują, a różnice są tylko logowane
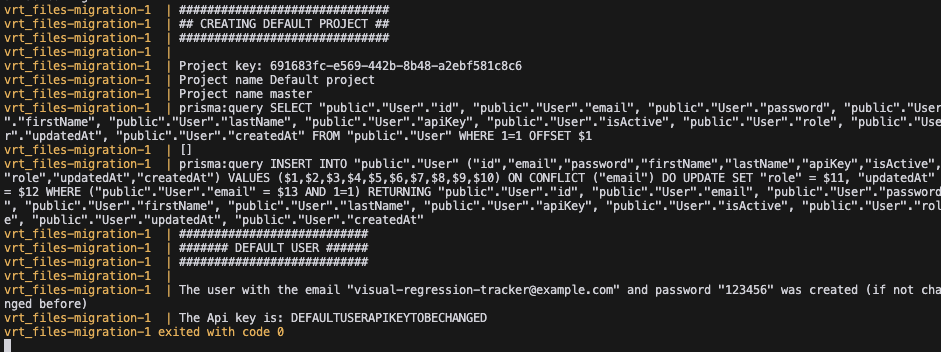
Oprócz klucza API do lokalnej instancji Visual Regression Trackera, w tym miejscu znajdziemy również informacje dotyczące wygenerowanego loginu i hasła. Jeśli domyślny sposób generowania tych danych nam nie odpowiada, możemy łatwo go zmienić, edytując plik seed.ts i modyfikując dwie zmienne (zaznaczone na czerwono).
https://github.com/Visual-Regression-Tracker/backend/blob/master/prisma/seed.ts

Logowanie się do Visual Regression Trackera
Po zalogowaniu naszym oczom ukazują się domyślne szczegóły naszego projektu.

W tym miejscu możemy zmienić nazwę projektu, ustawić domyślny branch, a także skonfigurować podstawowe ustawienia związane z tzw. thresholdem (progiem akceptacji różnic wizualnych). Threshold określa, jak bardzo nasza strona może się różnić od wzorca. Zbyt niska wartość może powodować generowanie dużej liczby false positive – czyli sytuacji, w których test zgłasza błędy mimo braku istotnych zmian wizualnych. Natomiast zbyt wysoka wartość może skutkować niewykrywaniem istotnych zmian wizualnych.
Konfiguracja połączenia z Visual Regression Tracker
Aby połączyć się z naszym rozwiązaniem, musimy dodać klucz API, który umożliwi przesyłanie wyników naszych testów automatycznych do zainstalowanej instancji Visual Regression Trackera.
Dane te można ustawić za pomocą JavaScriptu lub pliku .json. Osobiście preferuję użycie pliku .json, ponieważ na CI (Continuous Integration) łatwo można podmieniać wartości w takim pliku lub mieć różne zestawy konfiguracji zapisane w oddzielnych plikach.
Jakie mamy możliwości ustawień?
Mamy możliwość zrobienia zrzut ekranu dla całej strony za pomocą metody trackPage lub poszczególnych elementów dzięki metodzie trackElementHandler.
Metoda trackPage
Umożliwia ona nie tylko nadanie nazwy zrzutowi ekranu, ale także wykorzystanie różnych parametrów, które decydują o sposobie wykonania testów wizualnych. Parametry te pozwalają na dostosowanie działania testów w zależności od potrzeb i specyfiki strony.
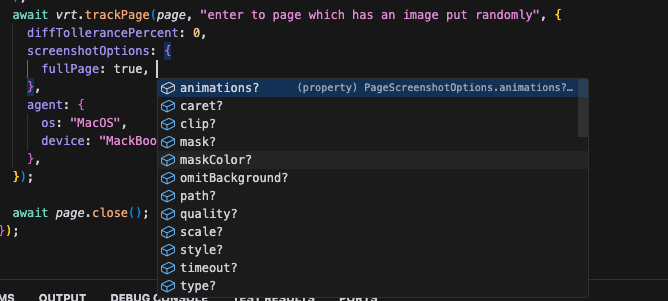
W tym miejscu możemy zdefiniować, czy chcemy wykluczyć animacje podczas robienia zrzutu ekranu, czy wykonać zrzut ekranu całej strony, a także skorzystać z maski oraz określić jakość generowanych zrzutów ekranu.
Dostępnych opcji konfiguracji jest więcej niż w domyślnym mechanizmie wykrywania regresji wizualnych dostępnym w Playwright zaraz po instalacji, co pozwala na bardziej precyzyjne dostosowanie testów do naszych potrzeb.
Zrobienie porównania elementów
Oprócz możliwości wykonywania testów dla całej strony, Visual Regression Tracker oferuje również opcję porównywania wybranych elementów na stronie. Może to być szczególnie przydatne w sytuacjach, gdy wiemy, że część strony jest dynamiczna i jej wygląd może się zmieniać, a mimo to chcemy sprawdzić poprawność wyświetlania określonych elementów – na przykład dla różnych systemów operacyjnych czy przeglądarek.
Zaczynamy pracę z Visual Test Regression ! Pierwszy test
Aby skorzystać z Visual Regression Trackera w naszych testach, musimy odpowiednio zdefiniować jego działanie w kodzie. Przechodzę do utworzenia nowego testu. Na początku należy użyć metody vrt.start(), która inicjalizuje działanie Visual Regression Trackera.
Następnie, warto od razu zdefiniować metodę vrt.stop(), która zatrzymuje działanie i umożliwia przesłanie wyników testów do zainstalowanej instancji Visual Regression Trackera.

Następnie przechodzę do zdefiniowania mojego testu

Wprowadziłem zmianę w teście poprzez zmianę adresu strony testowej strony dla naszego przykładu. Tak, aby przesunięcie elementów na stronie było widoczne.

Po uruchomieniu testu naszym oczom ukazuję się komunikat o błędzie. Również w Visual Regression Trackerze jest to widoczne.


W tym miejscu możemy sami zdecydować, czy wykryta zmiana jest spodziewana – na przykład, gdy frontend developer wprowadził oczekiwaną modyfikację w interfejsie użytkownika. W takim przypadku możemy zatwierdzić najnowszy zrzut ekranu jako nowy baseline, klikając przycisk „approve”. Jeśli jednak uznamy, że zmiana jest nieprawidłowa, możemy ją odrzucić, oznaczając jako błąd.
Na potrzeby tego artykułu uznaję, że jest to błąd, dlatego w Visual Regression Trackerze test otrzymuje etykietę „failed”.

Podczas ponownego uruchamiania testu wystąpił błąd w IDE, a z punktu widzenia Visual Regression Trackera wynik został oznaczony jako „unresolved” (zamiast „failed”). Oznacza to, że – podobnie jak przy poprzednim uruchomieniu – musimy ręcznie zdecydować, czy zmiana jest błędem, czy spodziewaną modyfikacją. Visual Regression Tracker jedynie rejestruje, że nastąpiła zmiana, ale nie potrafi samodzielnie określić, czy jest ona poprawna.
Ustawienie parametru ?mode=random&pixel_shift=1200 powoduje, że obraz zmienia swoją pozycję w sposób pseudolosowy przy każdym uruchomieniu testu, co skutkuje takim samym wynikiem „unresolved”. Aby uzyskać bardziej przewidywalne rezultaty, wracam do podstawowego adresu URL tej strony, eliminując element losowości.
Jeśli planujecie korzystać z Visual Regression Trackera lub innego narzędzia do wykrywania potencjalnych zmian wizualnych, warto pracować na stabilnych środowiskach. Najlepiej porównywać dwa środowiska, np. staging (zawierające produkcyjną wersję strony) i develop (z wersją deweloperską), aby zminimalizować szum informacyjny i sprawić, by narzędzie faktycznie wspierało wykrywanie istotnych zmian, zamiast wprowadzać chaos.
Jak zrobić screenshot na podstawie jednego elementu
Żeby robić zrzut ekranu dla jednego elementu należy użyć metody trackElementHandle.

Aby zrobić zrzut ekranu dla pojedynczego elementu, najprostszym sposobem jest znalezienie elementu na podstawie selektora. Na poniższym przykładzie najpierw wyszukiwany jest element z selektorem h1, następnie wykonywany jest zrzut ekranu tego elementu, który zostaje przesłany do Visual Regression Trackera.
Metoda trackElementHandle oferuje wiele przydatnych opcji. Możemy określić, który element ma zostać użyty, czy zrzut ma być wykonany wraz z tłem, jaką nazwę ma mieć zrzut ekranu oraz skorzystać z innych dodatkowych parametrów.
Jeżeli mamy stronę, na której dany selektor występuje więcej niż raz, możemy rozważyć wykonanie zrzutu ekranu dla każdego z tych elementów, używając tej metody.

Podsumowanie
W tym artykule przedstawiłem, jak możemy podejść do tematu visual regression w testach automatycznych z wykorzystaniem Playwright. Dzięki takiemu podejściu mamy możliwość wykrywania potencjalnych błędów wizualnych, które mogą pojawić się w aplikacji po wprowadzeniu zmian.
Jest to szczególnie przydatne w przypadku stron sprzedażowych, gdzie nawet drobne zmiany w interfejsie użytkownika mogą powodować problemy wpływające na konwersję i doświadczenie użytkownika.




")